Data Lake Integration
Introduction
Benchling customers may use Data Lakes to store a wide variety of scientific data. Scientists, Data Scientists, and Engineers may be interested in storing Benchling data into a data lake for data analysis purposes. Using Benchling’s Developer Platform, Benchling customers can integrate data from their Benchling instance to their Data Lakes. This integration gives end users and scientists a smooth experience, allowing them to interact with critical data with the least amount of effort.
Definitions
Terms & Concepts
| Term | Definition |
|---|---|
| Data Lake | Collection of raw data from sources across an organization (more below!) |
| Polling | A technical pattern that describes processing or fetching data in a regular, scheduled manner |
| Benchling Data Warehouse | A read-only SQL database that reflects your data in Benchling. |
Required Benchling Products
This technical accelerator relies on the Benchling Registry, Benchling Apps, Benchling API and optionally, the Benchling Data Warehouse.
Scope
The information in this document is intended to provide a general overview of data lake integration approaches using the Benchling developer platform. Customer informatics infrastructure varies significantly so implementation details may vary. Benchling's Technical Solutions team is available to discuss alternative solutions.
Overview
What is a Data Lake?
A data lake is a collection of raw data from sources across an organization. The data sources can be structured like relational databases, semi-structured like Excel, unstructured like PDFs, API endpoints of cloud applications like Benchling, or binary files stored on a filesystem. Typically the target users for a data lake are data scientists. The data stored in a data lake is often tagged with metadata to facilitate retrieval.
Data lakes can be confused with data warehouses, some customers may refer to their data warehouse as a data lake. A key differentiator between a data warehouse and a data lake is the type of data that is stored in a data lake is raw and unprocessed, a data warehouse stores processed, transformed, and structured data. Another differentiator is that a data warehouse is always architected around a relational database schema which end users access directly. Data lakes use multiple technologies in their architecture to store the data and access is abstracted from the discrete data storage technologies.
A data lake works on the principle of schema-on-read which means there is no predefined schema into which the data needs to be fit for storage. Because there is no predefined data storage schema, data can be stored
in a data lake in raw form. When a user reads the data in a data lake it is processed and transformed on demand and adapted to a schema as needed.
High Level Integration Diagram
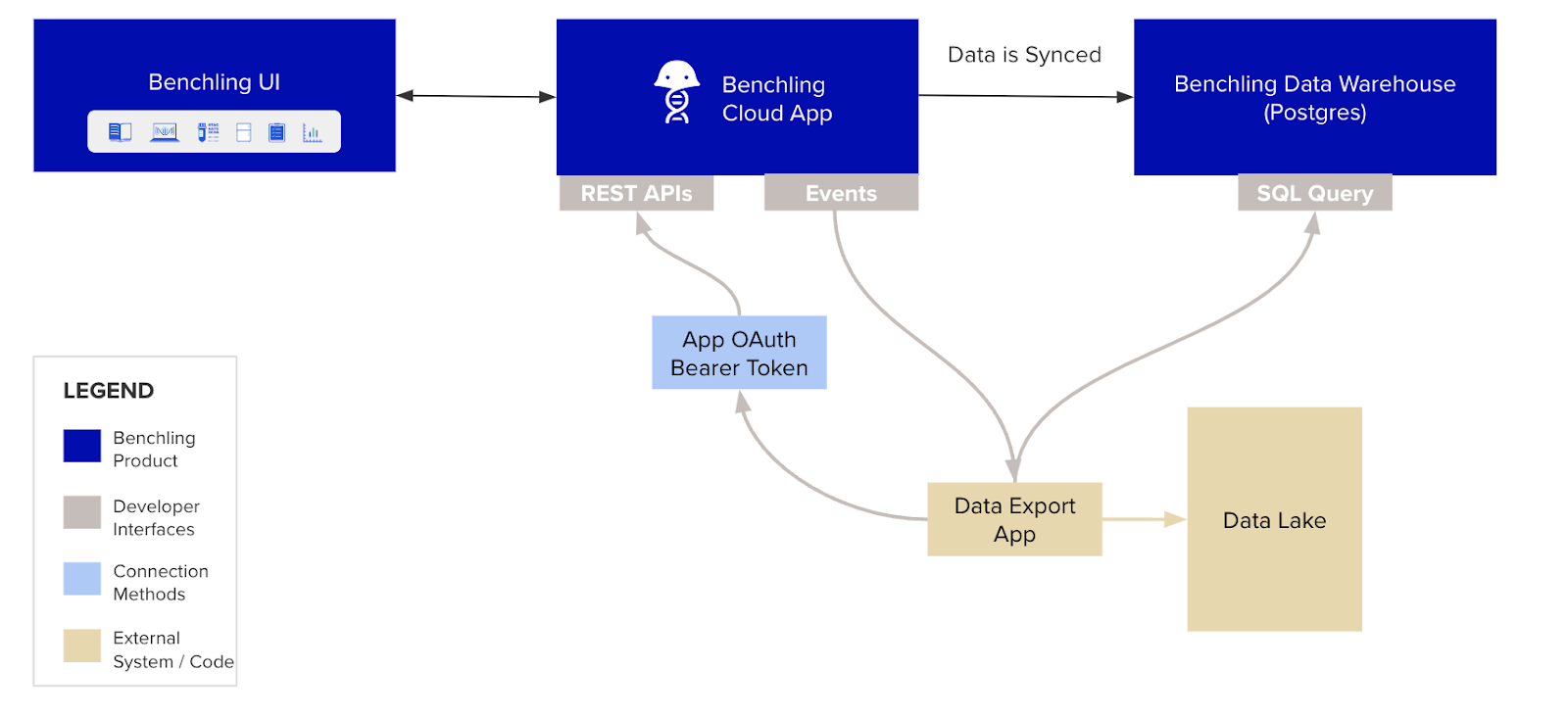
General Components of a Data Lake Integration
Data Export
The Benchling API and Data Warehouse are the two methods that can be used to access data from Benchling that is to be inserted into a Data Lake. The data export method should be chosen based on the customer requirements.
Polling for Change Monitoring
The primary method of monitoring for changes in Benchling is done through polling against the Benchling API. A polling script can then be used to pass the change information on to data insert scripts that take the necessary action in the data lake like creating a new entity.
A typical polling script will need to identify objects that have been changed since the last time a run of the script was completed. The API list endpoints for custom entities, DNA sequences, AA sequences, and Results all support a modifiedAt filter to return a list of entities that have changed in a time range.
Event-Based Change monitoring
Certain changes within Benchling can be tracked using Events; Benchling Events are built on a framework that uses Amazon Event Bridge to record changes that happen in Benchling, for example a new entity is registered. Our current list of supported events are outlined in the Events Reference. The registration event recorded in Amazon Event Bridge can then be used to trigger any scriptable action like getting new entity information from the Benchling API and recording it in a data lake. Given the limited types of actions, event-based change monitoring is typically supplemental to a polling-based approach.
Data insert script
Once changed data in Benchling has been identified a data insert script is built that writes the changes into the Data Lake. Development of data insert scripts is owned by the customer or the Benchling customer engineering team. Change monitoring and data insert are often combined into a single integration script.
Approaches for Exporting Data from Benchling
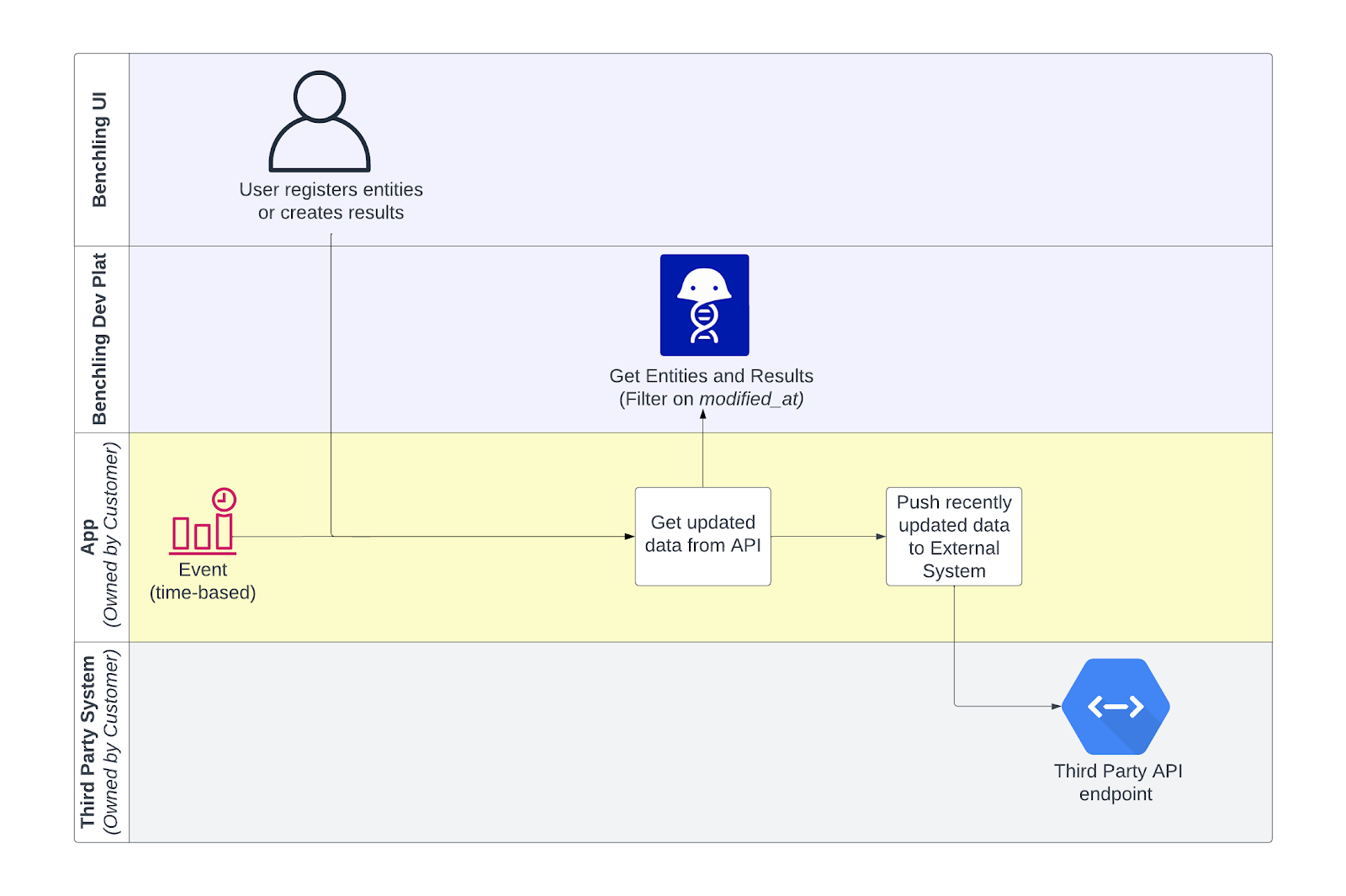
Benchling API + Polling Script
- Syncing newly created entities, containers, results or other API-accessible information to a data lake.
- Realtime or scheduled data sync from the core Benchling database.
- Use for integrations that both create new entities and update existing entities in the data lake.
Limitations:
- Requires customer developer resources who are familiar with web APIs and scripting or a CE Integration/Partner.
- Not event-driven
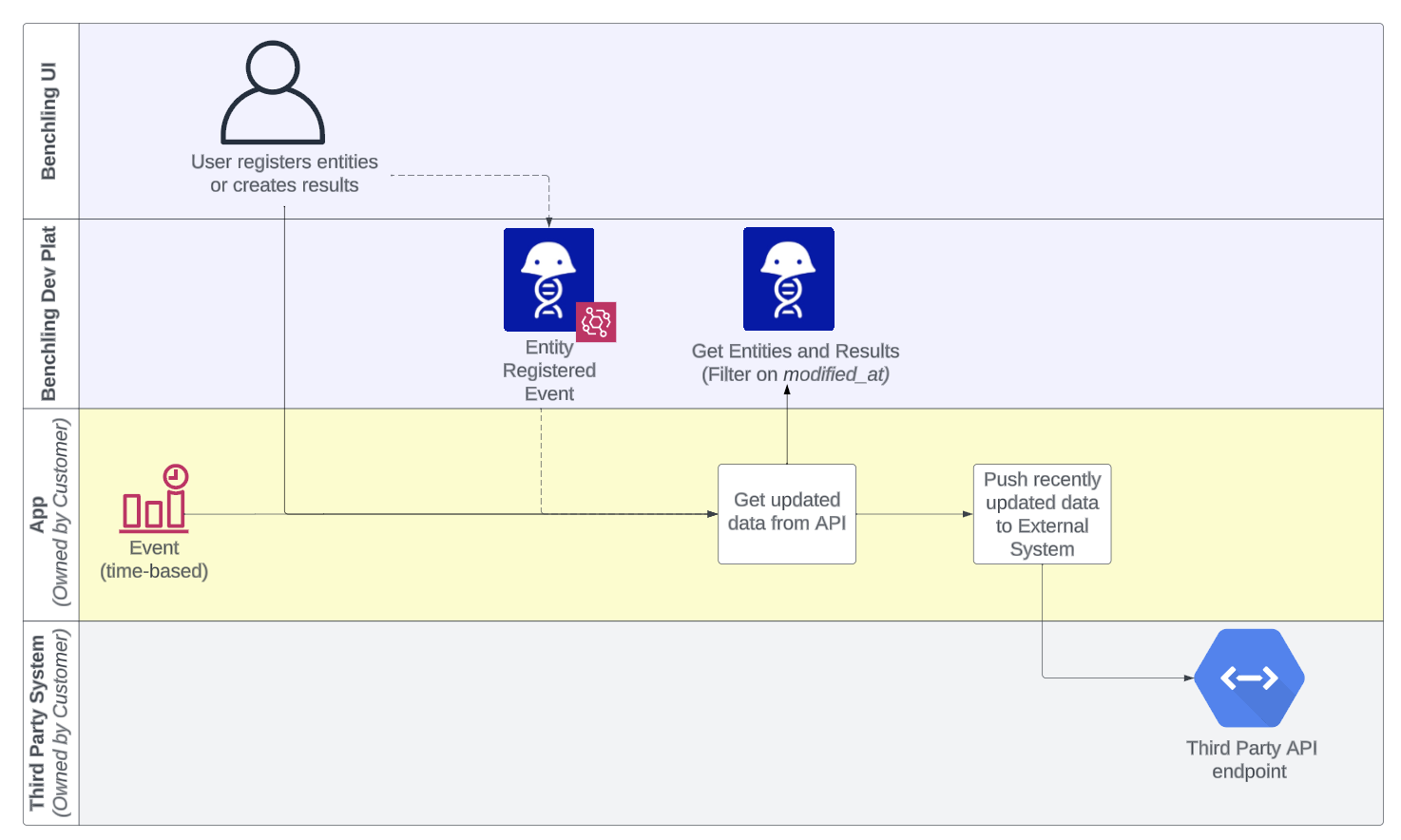
Benchling API + Events
- Syncing newly created entities, containers, results or other API-accessible information to a data lake
- Realtime data sync from the core Benchling database
- Benchling Events track all the newly created entities
- No polling necessary
- Can be added to a polling script to reduce latency for certain use cases
Limitations:
- Benchling Events are triggered only on a specific set of schemas/entities. Generally also requires a Polling Script
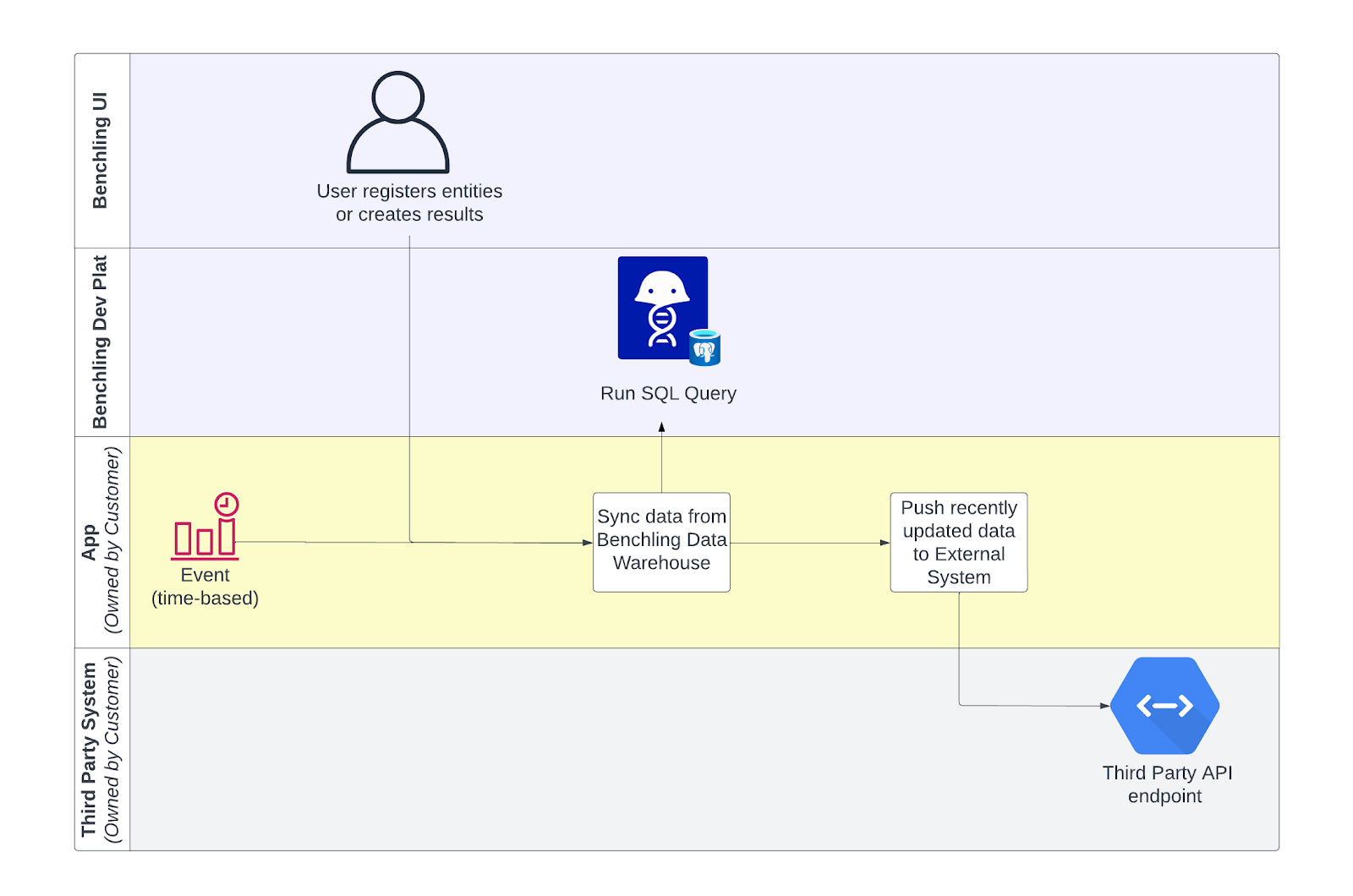
Data warehouse
- Choice for data lake integrations when it's not possible to use the Benchling APIs or customer requires the use of structured queries.
- Convenient when the goal of the integration is to pull all tables of a certain schema type from Benchling to corresponding tables in the data lake.
Limitations:
- Requires a customer database administrator to set up and maintain.
- Changes to Benchling schemas like archiving or adding new fields can break the integration.
- Not real time, can be a lag of up to 24 hours between when a result or entity is created in the Benchling core database and is synced to the Benchling data warehouse.