
Developer Platform Overview
The Benchling Developer Platform allows you to programmatically access and edit data in Benchling. The platform is most commonly used for:
- Keeping Benchling in sync with other systems
- Bulk Loading/Exporting data
- Creating dashboards and charts of Benchling data
- Integrating with Instruments in the lab
These different activities are accomplished through several different developer tools and interfaces that we offer in the Developer Platform, as pictured in the high-level architecture diagram below:
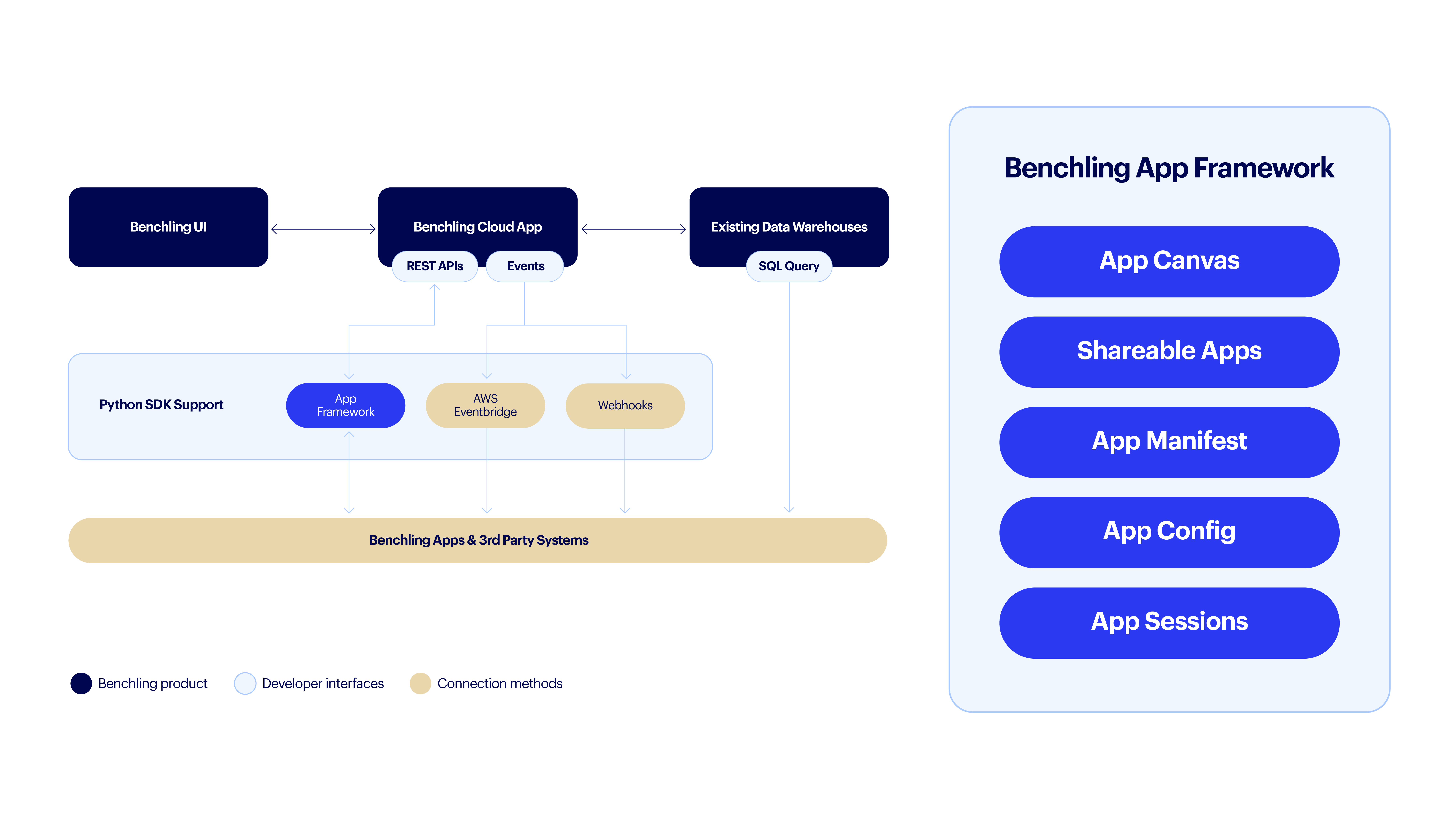
Each of the top use cases can be accomplished through a variety of the tools and interfaces in the above diagram, and we’ve broken out our recommended methods in the Use Cases section below, along with links to dive deeper into each of these systems. Or you can simply jump to our Key Links section to see everything the developer platform has to offer.
Accessing the Developer Platform
To access the Developer Platform, each user that requires it needs to have the “Developer Platform” access set to “Full” in the Capability Management tool. To do this, you must be a Tenant Admin, access the Tenant Admin Console, and navigate to the “Users” tab:
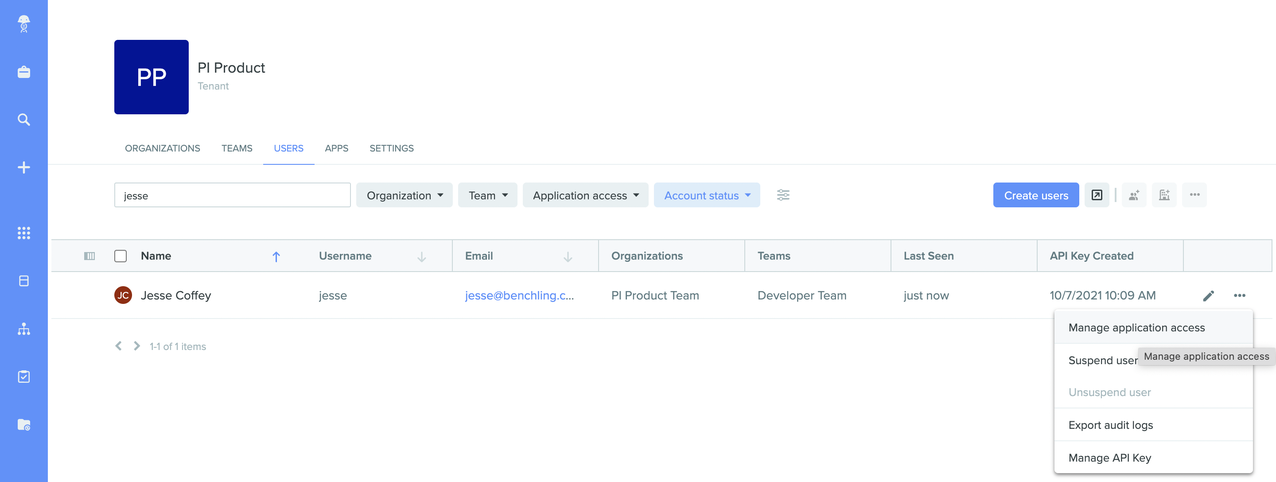

After getting access, make sure to generate your personal user API key on your user settings page, as it gives you access to the interactive API reference documentation. See the "Setup" section of the Overview & Tutorial for where to find it.
If you'd like more information on how to set up the Developer Platform capability, see our help article.
Common Use Cases
Keeping Benchling in sync with other systems
When integrating Benchling and another system, typically you’ll want to leverage a Benchling app and the REST APIs, as shown below:
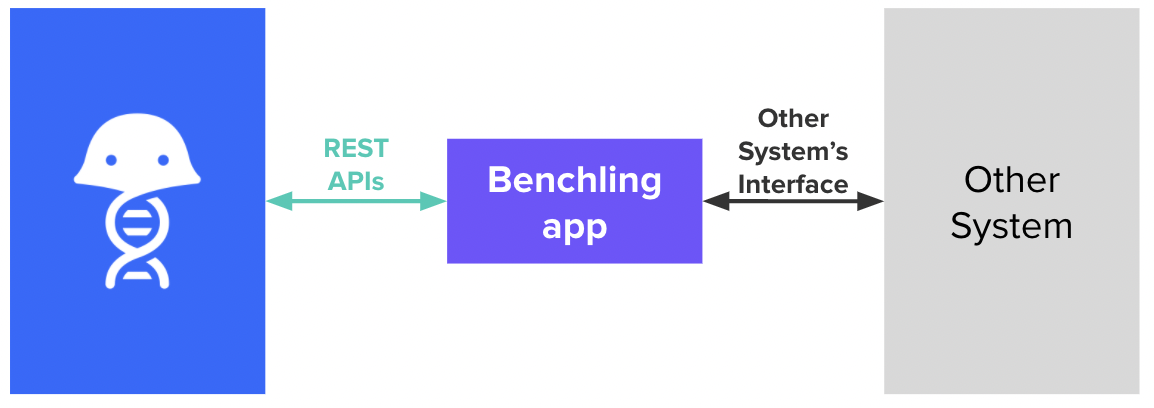
This is primarily due to the following:
- You likely need access to both read and write data
- You likely need the data to be guaranteed latest, and cannot wait for changes to be synced to the warehouse
- You likely need to limit the amount of data that the integration with the other system can have access to
You can check out how to get started building this type of app in our Getting Started with Benchling Apps guide. We highly recommend using the Python SDK if you’re comfortable in Python.
Advanced Feature - Evented Apps
If you want to reduce the amount of polling your app needs to do or build a feature that triggers off actions in Benchling, you’ll want to set up Events and route them to your app. Note that this does require using AWS Eventbridge, as it is the only delivery method we currently support for events. Check out the Events Getting Started guide for how to begin, and our Request + Slack integration walkthrough for an example evented app.
Advanced Feature - Authenticating as any User
If Benchling users are interacting directly with another system, you might want to ensure that the changes they are making in those other systems are reflected in Benchling’s audit and activity systems, or leverage Benchling’s permissioning system. If you need your app to make calls as any user in Benchling (not just 1, like through their API key), it requires setting up OIDC Authentication between Benchling and your IDP. See more about this process in the OIDC Section of the Authentication guide. Note that the Python SDK currently does not support OIDC authentication.
Bulk Loading / Exporting Data
Bulk loading / exporting data through developer interfaces can be necessary for a variety of reasons, but essentially it comes down to just needing to have the control that code can provide. Benchling’s developer interfaces have a variety of methods for data ingest and egress. This section won’t provide the exhaustive list, but rather provide some high level guidelines.
Data Ingest
The only developer interface that supports writing data into Benchling is the RestAPIs. Even still, your solution could take a variety of different forms.
If you’re writing a script that is intended to be used once or run directly by a user, leveraging the user API key is the simplest and most straightforward way to make the calls. Their actions will be accurately represented in Benchling’s audit and activity logs. Check out our API Tutorial to get started, and check out our API Reference to see what kinds of data you can write to Benchling.
If you’re writing a persistent or long-running application that regularly uploads data to Benchling, you’ll likely want to create a Benchling app to make sure it isn’t attached to a single user. Check out the getting started with Benchling apps guide to do so.
Regardless of your choice, we highly recommend using the Python SDK if you’re comfortable in Python, as it supports both methods.
Once you’ve completed the getting started guides, you can walk through a richer example of how to write data to the APIs with our Results upload guide.
Data Export
Exporting data is generally best accomplished through the RestAPIs as well, again using a user API key for one-offs scripts and Benchling apps for more persistent use cases and using the Python SDK if you’re comfortable in Python.
If you’re more comfortable in SQL or need very large amounts of data, and you do not need the data to be “live” up to the minute, you can also leverage the Benchling Data Warehouse. Check out the Warehouse guide to learn more and get started accessing it.
Creating dashboards and charts of Benchling data
While Benchling allows you to natively visualize data in Insights, it also supports other analytics tools as well via the warehouse connection. Benchling’s Data Warehouse provides a SQL database connection that can be used in a variety of ways to richly query your Benchling data. You can use common 3rd party visualization tools (see guide here) to connect directly and query your data out of the box, or you can connect from a Jupyter notebook (see guide here) and tools like it. Make sure to check out the Warehouse Guide for more information on how to get started.
If you don’t have access to the Benchling Data Warehouse, you can also leverage the Rest APIs to query your data using your user API key. They are also accessible in environments like Jupyter, and especially easy if you’re using the Python SDK. If you’re not using Python, you can still make calls directly using your language of choice. Check out the API Tutorial or Python SDK guide to get started.
Writing back analysis results
Regardless of the method you use to query the data, writing data back to Benchling is only possible via the Rest APIs. See our Results upload guide for an example of this.
Integrating with Instruments in the lab
Instruments are a key part of any lab ecosystem. If you’re looking to automate your workflows or data collection, you can leverage Benchling’s developer platform to connect Benchling to your instruments automatically. Generally we recommend using a Benchling app to represent the instrument within Benchling:
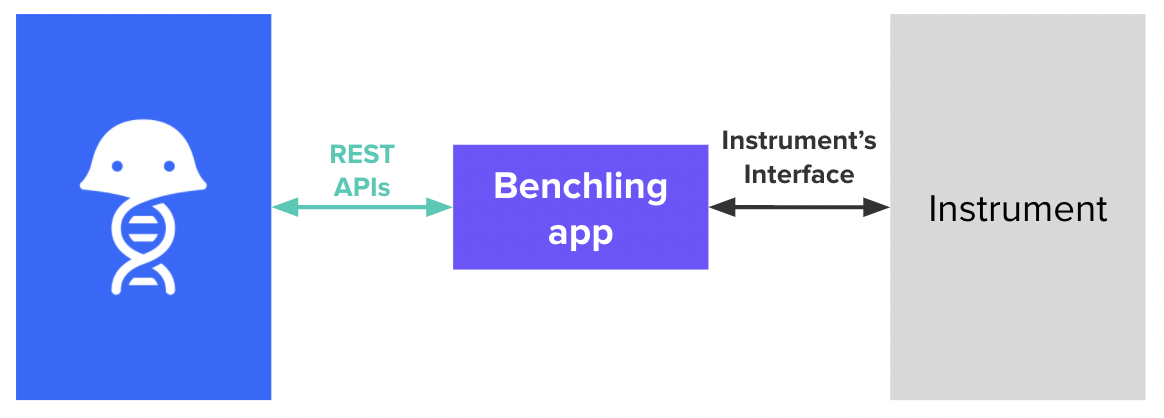
You can then permission the app to allow it access to write data to the appropriate places and track its activity independently.
To get started with Benchling apps, check out the Benchling app Guide to understand how to set up the app.
Once you’ve gotten set up, you can then check out our Results Upload on how to upload the results to Benchling directly.
If you want to integrate the instrument with the Notebook to capture input from a user or to surface the results in the Notebook UI, you'll need to use Benchling Connect. The Benchling Connect guide walks through the basics of how to get instrument files uploaded and processed in the Notebook.
Key Links
Updated over 1 year ago