
Analyses API Developer Guide
Introduction
The Analyses API includes a number of endpoints for working with the Benchling Analysis product. Integrators can leverage the import/export functionality of Benchling analyses to allow users to interact with external systems. Integrations can use these features to pull Benchling data for external analysis, and upload post-analysis data files.
The goal of this developer guide is to walk through how Benchling users interact with the Analyses product, and how apps can extend an analysis through a import/export. This includes discussing Analyses API endpoints in more detail, as well as core concepts such as analysis keys. Like most integrations, we recommend Analysis integrations use app authentication; before working with the Analyses API, make sure you’re familiar with building Benchling Apps.
Getting Started
Before diving in, it’s worth taking a closer look at how Benchling users create analyses to process their data. Benchling analyses include the following:
- Analysis object - Objects that allow users to view and analyze experimental result data
- Data frames - Tabular data used in analyses
- Files - Raw files (images, text, HTML)
The way that apps can interact with Analyses is through the import/export feature, which enables an integration to both export data frames from Benchling, and import data frames and files into Benchling. To users, this all occurs as a part of a single action in their Benchling Analysis.
Analysis Integration User Flow
Users interact with the import/export functionality in the following way: First, a user copies the Analysis Key from the import/export in Benchling. Next, they provide the key to the integration through an external UI. Finally, the user returns to the Benchling Analysis, where the external system has sent the data frame.
While the purpose of an Analysis integration could be to process or analyze data by an external platform, the following components are also crucial:
- A UI for accepting an Analysis Key
- A mechanism for pulling data frames from Benchling
- A mechanism for pushing data frames and files to Benchling
Analysis Key
An analysis key is a value provided to Benchling users when working with the import/export feature. The analysis key is composed of the relevant analysis_id, as well as a JSON Web Token (JWT), separated by a colon (:). The analysis_id is the internal Benchling identifier for the relevant analysis, and the JWT can be used to authenticate requests to the customer’s tenant.
Here’s an example key:
ana_ABCD1234:eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyfQ.SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c
The JWT tokens associated with analysis keys expire after 10 minutes, after which users must generate a new one. A new key is generated each time a Benchling user copies one from the import/export dialogue, so if you're using the key to authenticate be sure to prompt for a new key each time a user is running the external analysis.
While analysis keys include a JWT that can be use to authenticate requests, this is not a best practice. Analysis key authentication can be used for testing, but due to the 10-minute expiration should not be used for production applications. Consider creating a Benchling App and using app authentication instead.
The JWT payload portion of an analysis key contains information about the customer’s tenant, including a unique tenant identifier. This is particularly important when building multi-tenant apps; below is a Python example of working with analysis keys:
# Separating the analysis_id value from the JWT
analysis_id, key = analysis_key.split(":")
# Splitting the JWT into it's consitituent parts
_headers, payload, _signature = key.split(".")
# Decoding the JWT payload (Note: this example uses the b64decode library)
jwt_payload = json.loads(base64.b64decode(f"{payload}=="))
tenant = jwt_payload["aud"]Downloading data frames from Benchling
Users start an analysis by creating an initial data frame from registry data, from a dashboard query, or from existing tabular data. Check out the Benchling Help Center for more information on how users interact with the Registry and Insights tools.
This initial data frame is the foundation of the analysis, and is the starting point for creating views and importing/exporting other files and data frames. Data frames are the main object that Analyses can work with, and an Analyses can work with multiple data frames at once.
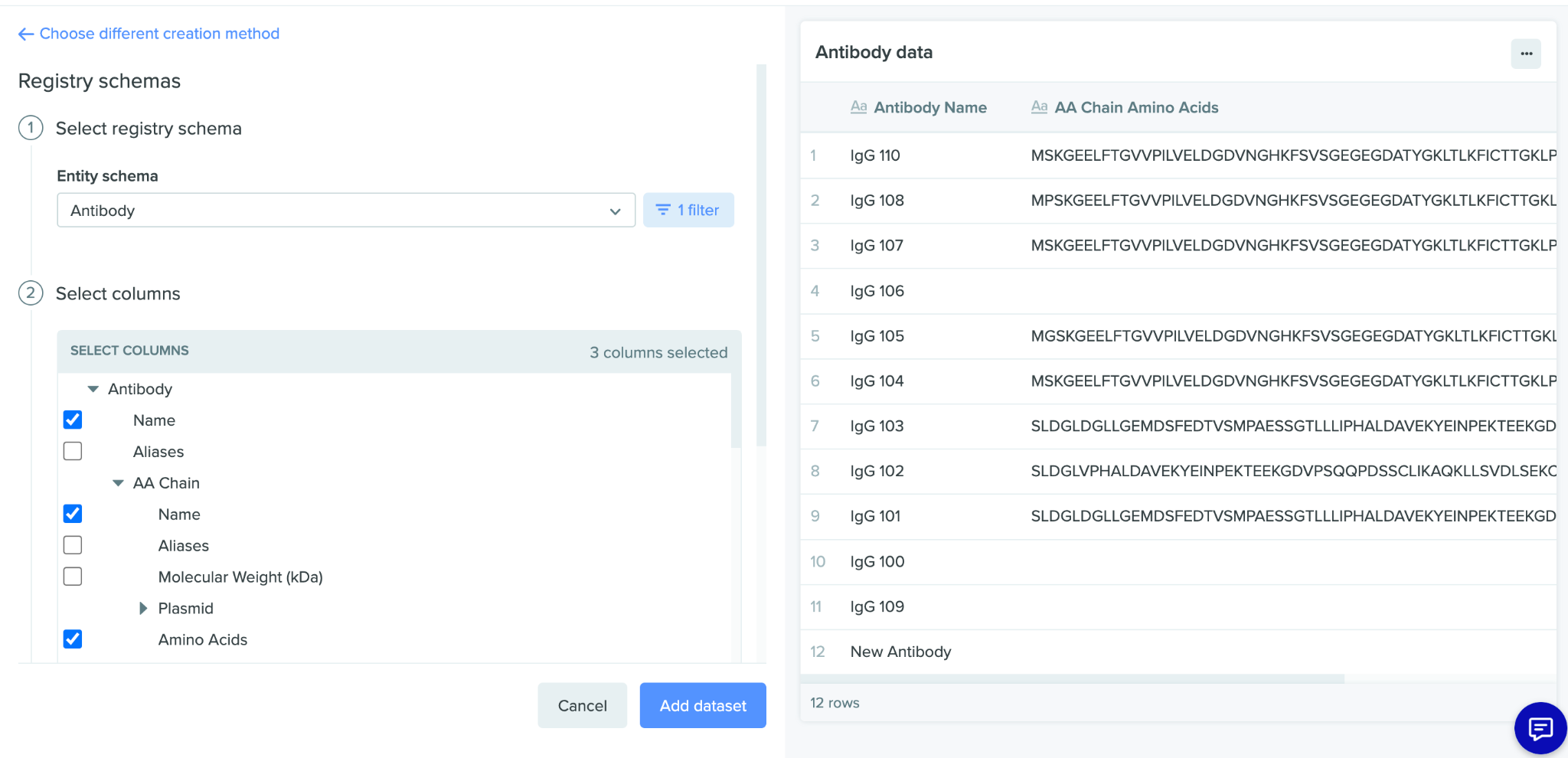
Imports/exports begin with obtaining the relevant input(s); using the Get an analysis endpoint (i.e. GET /v2-beta/analyses/:analysis_id) returns an analysis object (seen below). Note that there may be multiple data frames/files returned; each analysis can have any number of data frames and files to download.
{
"id": "ana_DjEC6xL4",
"dataframesIds": [
"dset_t69ysPGQUl4H",
],
"fileIds": [
"file_UoqJSDwI"
],
"folderId": "lib_Gfjd3i1m"
}Data frame inputs
With the data frame ID from the dataframesIds array, we can query the Get a data frame endpoint (i.e. GET /v2/data-frames/:dataframes_id) to get the relevant metadata for the data frame. There are a number of important details provided:
uploadStatus- This field denotes the current status of the data frame. The upload status can be any ofIN_PROGRESS,SUCCEEDED,FAILED_VALIDATION, orNOT_UPLOADED(for the purposes of getting an initial data frame, we’re only concerned withSUCCEEDEDdata frame).manifest- This field is a list of the files that make up the data frame; each file is represented by an object including the name and url. The value of theurlfield varies depending on the data frame’suploadStatus:- For
SUCCEEDEDdata frames, the value is the file’s download url. - For
NOT_UPLOADEDdata frames, the value is a pre-signed url used to upload a file via the Update a data frame endpoint (i.e.PATCH v2-beta/data-frames/{dataframesid}). - For all other statuses, the
urlfield will benull.
- For
For data frames with an uploadStatus of SUCCEEDED , the url field of the files are pre-signed urls that can be used to download the data frame CSV data. Here’s an example data frame:
sample,ct,ct_mean,quantity,quantity_mean
qPCR Sample 15,17.453,17.419,0.245,0.251
qPCR Sample 14,17.364,17.257,0.26,0.28
qPCR Sample 13,16.481,16.43,0.469,0.486
qPCR Sample 12,30.507,30.345,0.01,0.011
qPCR Sample 11,30.072,30.345,0.01,0.011
qPCR Sample 10,30.456,30.345,0.01,0.011
qPCR Sample 9,22.175,22.144,0.01,0.011
qPCR Sample 8,22.106,22.144,0.011,0.011
qPCR Sample 7,22.152,22.144,0.011,0.011
qPCR Sample 6,17.316,17.306,0.269,0.271
qPCR Sample 1,11.115,11.142,16.858,16.568File inputs
Like data frame inputs, we can use the file ID(s) from the fileInputs array to query the Get a file endpoint (i.e. GET /v2/files/{file_id}) and get metadata about the file:
{
"errorMessage": null,
"uploadStatus": "SUCCEEDED",
"id": "file_Of5GuBSq",
"name": "IC50Chart",
"filename":"IC50Chart.png",
"folderId": "lib_Gfjd3i1m"
}Unlike data frame inputs, the response doesn’t contain a manifest field; instead, a Content-Location header includes the pre-signed URL where the file can be downloaded.
Uploading data frames and files to Benchling Analysis
Once an integration has successfully completed an external analysis, the final product is uploaded back to the Benchling Analysis. Both data frames (in the case of tabular data) or files (in the case of images or other file types) can be pushed back to the Benchling Analysis.
Pushing data back involves creating the data frame or file definition in Benchling, uploading the relevant data to the Analysis.
Files must live in a folder!Files are first-class objects in Benchling, and therefore require a location when they are created; this is represented by the required
folderIdparameter. Usually, files are created in the same folder as the associated analysis. Check out the Folders API for more info on folders in Benchling.
Importing new Data frames to a Benchling Analysis
Data frames can be created using the Create a data frame endpoint (i.e. POST /v2/data-frames) by first specifying the data frame’s manifest, including the name of the data frame or the file to be uploaded:
{
"manifest": [
{
"fileName": "09-14-2022_011620_PM_well_plate-part-00000.csv"
}
],
"name": "09-14-2022 01:16:20 PM well plate"
}The response to this request includes a complete data frame object with a status of NOT_UPLOADED; the manifest now includes a pre-signed URL and a data frame ID:
{
"errorMessage": null,
"id": "dset_LlDFupKyErxx",
"manifest": [
{
"fileName": "09-14-2022_011620_PM_well_plate-part-00000.csv",
"url": "https://benchling-location.s3.amazonaws.com/deploys/location/data_frames/source_files/.../09-14-2022_011620_PM_well_plate-part-00000.csv?..."
}
],
"name": "09-14-2022 01:16:20 PM well plate",
"uploadStatus": "NOT_UPLOADED"
}Using the url, the CSV can be uploaded to Benchling; be sure to include the x-amz-server-side-encryption: AES256 header to work with Benchling’s server-side encryption. Here is a curl example:
curl -H "x-amz-server-side-encryption: AES256" -X PUT -T <LOCAL_FILE> -L <S3_PUT_URL>Finally, update the status of the data frame to IN_PROGRESS using the data frame ID and the Update a data frame endpoint (i.e. PATCH /v2/data-frames/{dataframesid}).
{
"uploadStatus": "IN_PROGRESS"
}This endpoint is asynchronous; successful request returns a 202 Accepted and an empty response body. A successful request launches the process to validate and transform the uploaded CSV into a data frame. Once complete, the data frame's status will be automatically updated to SUCCEEDED or FAILED_VALIDATION.
Importing new Files to a Benchling Analysis
File imports follow a nearly identical process, with a couple of slight differences. First, a file definition is created in Benchling using the Create a file endpoint (i.e. POST /v2/files):
{
"name": "IC50Chart",
"filename":"IC50Chart.png",
"folderId": "lib_Gfjd3i1m"
}This creates the file definition in Benchling, and similar to data frames a file ID and pre-signed URL is returned:
{
"errorMessage": null,
"id": "file_Of5GuBSq",
"name": "IC50Chart",
"filename":"IC50Chart.png",
"folderId": "lib_Gfjd3i1m",
"uploadStatus": "NOT_UPLOADED"
}Notably, the upload URL is not included in the response body. Instead, the url can be found in the Content-Location header. The file can be uploaded to the url (including the x-amz-server-side-encryption: AES256 header):
curl -H "x-amz-server-side-encryption: AES256" -X PUT -T <LOCAL_FILE> -L <S3_PUT_URL>Finally, update the status of the file definition; unlike data frames, there is no validation and conversion performed on the file, so the status can be set directly to SUCCEEDED :
{
"uploadStatus": "SUCCEEDED",
"folderId": "lib_Gfjd3i1m"
}Benchling supports a maximum file size of 30MB. Currently supported file types include .html, .jmp, .jrn, .jrp , .jpeg, .jpg , .png, .csv, and .txt.
End-to-End Example
An example of this file upload process in python can be found here:
import json
import os
import requests
# Calls should be authenticated using the
# app's OAuth access token
token = os.environ['TOKEN']
tenant = "my.benchling.com"
# For file uploads:
filename = "myfile.txt"
name = "My File"
# Create file definition in Benchling
file_post = requests.post(
f"https://{tenant}/api/v2/files",
data=json.dumps({"filename": filename, "folderId": "lib_lOAKZhDQ", "name": name}),
headers={"Authorization": f"Bearer {token}", "Content-Type": "application/json"},
)
# Store the upload URL and file_id
file_post_resp = json.loads(file_post.content)
bench_put_url = file_post.headers["Content-Location"]
file_id = file_post_resp["id"]
# Upload file contents to Benchling
bench_put = requests.put(
bench_put_url,
data=open(filename, "rb"),
headers={"x-amz-server-side-encryption": "AES256"},
)
# Update the file object in Benchling to indicate success
file_patch = requests.patch(
f"https://{tenant}/api/v2/files/{file_id}",
data=json.dumps({"uploadStatus": "SUCCEEDED"}),
headers={"Authorization": f"Bearer {token}", "Content-Type": "application/json"},
)
# For data frame uploads:
filename = "mydataframe.csv"
dataframename = "My Data Frame"
# Create data frame definition in Benchling
dataframe_post = requests.post(
f"https://{tenant}/api/v2/data-frames",
data=json.dumps({"manifest": [{"fileName": filename}],"name": dataframename}),
headers={"Authorization": f"Bearer {token}", "Content-Type": "application/json"},
)
# Store the upload URL and dataframe_id
dataframe_post_resp = json.loads(dataframe_post.content)
bench_put_url = dataframe_post_resp["manifest"][0]["url"]
dataframe_id = dataframe_post_resp["id"]
# Upload dataframe file to Benchling
bench_put = requests.put(
bench_put_url,
data=open(filename, "rb"),
headers={"x-amz-server-side-encryption": "AES256"},
)
# Update the dataframe object in Benchling to begin processing
dataframe_patch = requests.patch(
f"https://{tenant}/api/v2/data-frames/{dataframe_id}",
data=json.dumps({"uploadStatus": "IN_PROGRESS"}),
headers={"Authorization": f"Bearer {token}", "Content-Type": "application/json"},
)Associating data frames and files to an analysis
Once data frames and/or files from an external analysis have been uploaded to Benchling, they can then can be attached to the analysis. This requires updating the analysis to include the data frame(s) and/or file(s) using the Update an analysis endpoint (i.e. PATCH /v2-beta/analyses/{analysis_id}). Making addition request with data frames or files will append the new objects to the analysis.
// Attaching a data frame:
{
"dataframesIds": [
"dset_LlDFupKyErxx"
]
}patch_data = requests.patch(
f"https://{tenant}/api/v2-beta/analyses/{analysis_id}",
data=json.dumps({"outputData": {"dataframesIds": ["dset_LlDFupKyErxx"]}}),
headers={"Authorization": f"Bearer {{token}}"},
)Updated 11 months ago