
Limits
Why does Benchling have limits?The Benchling developer platform includes a wide variety of interfaces that touch nearly every aspect of the product, supporting complex and powerful apps and integrations. Because the developer platform is so deeply connected to the core Benchling product, we've designed a number of limits to protect the integrity and stability of the entire system. What follows is a description of the different types of limits that exist when working with the developer platform, as well as guidance on best practices for working within them.
Data Limits
For operations that involve batches of entities, Benchling has established limits on the amount of data that you can pull from, or push into, your tenant in a single request. Some common operations that involve data limits are bulk actions (e.g. :bulk-create), as well as list actions. The guidelines here cover the most common use case, but are not comprehensive; be sure to check out the description of the API(s) you're working with in our reference documentation for more details.
Pagination
Benchling paginates the results of all list endpoints, meaning that the response returned by these endpoints includes only a subset of the data that exists in your tenant (i.e. one "page"). Subsequent requests are made to get additional entities (i.e. the next "page"). The pageSize parameter is used to specify the number of entities returned from a specific endpoint; by default, this parameter is set to 50, and the maximum value for this parameter is 100.
Bulk Operations
A number of Benchling services support bulk operations, like :bulk-create and :bulk-update. While these operations are designed to support high throughput use cases, sufficiently large request bodies can result in timeouts or other issues. For bulk create operations specifically, we've imposed limits on the amount of data that can be included in a single request. For most :bulk-create endpoints, the limit is 1000 entities in a single request, though some specific services support larger limit sizes; the Bulk Create Custom Entities endpoint, for example, has a limit of 2500 entities per request. For sequence entities, performance can start degrading when the number of annotations and translations reaches the low thousands. Although there is no strict limit enforced, we recommend keeping the performance impacts in mind when conducting these bulk operations.
The limits for these endpoints can be found here:
| Endpoint | Entity Limit |
|---|---|
| Transfer into Containers | 5000 |
| Bulk create Custom Entities Bulk register Entities | 2500 |
| Bulk create AA Sequences Bulk create Containers Bulk create DNA Oligos Bulk create DNA Sequences Bulk create Mixtures Bulk create RNA Oligos | 1000 |
| Create 1 or more Result | 100 per request 10,000 requests per hour |
Total Payload Size
For any POST, PATCH, or PUT requests, total payload size is limited to 100MB. If you exceed this limit, Benchling will return a 413 Request Entity Too Large code.
Warehouse Direct Access Limits
For integrations that connect directly to the Data Warehouse, Benchling has established limits around concurrent connections and transaction duration. These limits ensure that updates can sync in a timely manner and the Warehouse is able to reliably serve queries. Additionally, this section includes best practice guidance for querying the Warehouse efficiently and within these limits.
Concurrent Connection Limits
Benchling enforces a limit on the number of concurrent connections that can be open against a Data Warehouse at both the User-level and the Warehouse-level:
User-level Connection Limit
A user can have no more than 100 concurrent open connections to a Warehouse. Attempting to open more connections will result in a FATAL: too many connections for role error.
If you encounter this error, check your codebase for connection leaks and/or consider implementing a strategy that doesn’t require opening as many connections (e.g. connection pooling)
Warehouse-level Connection Limit
Each Warehouse has a dynamic limit of concurrent open connections across all users based on system load. This includes connections Benchling internal systems make to maintain the Warehouse and perform data sync operations. Attempting to open more connections when the system is in this state will result in a FATAL: remaining connection slots are reserved for non-replication superuser and rds_superuser connections error.
This is uncommon, and generally occurs only when a large number of Warehouse clients are opening a larger than usual number connections. If you encounter this error, consider backing off from making direct connections for a time, and/or updating integrations to open fewer connections. If these errors are persistent, please contact Benchling support for guidance.
Warehouse Best Practices
In addition to the limits above, the following best practices are recommended for working with the Warehouse in a robust and scalable way:
Transaction Duration Best Practices
In some cases (e.g. query workload is interfering with the replication process) connections may be terminated. This is true particularly when long-running transactions hold locks on tables that must be modified during the sync of application data. Be prepared to handle connections that may be disconnected in a robust way, and consider the following:
- Avoid holding long-running transactions whenever possible
- Commit transactions as soon as they are complete
- Turn on auto-commit mode for sessions
Polling Best Practices
Integrations that poll the Warehouse for updates should limit their polling frequency to no more than 4-5 times per minute. Because the Data Warehouse is not updated in real-time, more frequent polling is unlikely to be useful. Benchling recommends this polling frequency for this reason, though this is not a hard limit imposed by the system.
Rate Limits
There are 2 types of rate limits implemented in Benchling:
- Request rate limits, which limits the volume of calls to the API
- Throughput rate limits, which limits the volume of data being created or updated
If either limit is reached, Benchling will respond to further requests with a 429 “Too Many Requests” response until the limit resets. Any requests met with this 429 error are not automatically queued for resubmission and must be called again.
5XX ErrorsBecause not all our API endpoints put the same amount of load on our system, it is possible to not use the entire rate limit bucket but still overload the system.
If you are getting 5XX level error codes, you should significantly back off or abort your process.
Request Rate Limits
If you make a lot of API requests in a short amount of time, you may hit an API rate limit. Benchling implements the following request limits by default:
- 60 requests per 30 seconds per tenant for all users keys
- 300 requests per 30 seconds per app key
- 1000 requests per 30 seconds per tenant for all Benchling apps (not included in the header response)
Each API response includes the following headers describing the current request rate limit status:
| Header | Description | Example |
|---|---|---|
| x-rate-limit-limit | The total number of requests allowed per period. | 60 |
| x-rate-limit-remaining | The number of requests remaining per period. | 57 |
| x-rate-limit-reset | The number of seconds remaining in the period. | 21 |
Throughput Rate Limits
A throughput limit is a limit on the total volume of data being created or updated in Benchling over a period of time. While the Data Limits and Rate Limits sections outline restrictions on the size and frequency of individual API requests, the throughput limits discussed here outline restrictions that apply across many requests over the course of hours.
The throughput limit is enforced dynamically based on the total number of objects created or updated over a given period of time. In this context, 'objects' refers to Benchling entities, containers, results, etc. The exact point at which the throughput limit is enforced changes in response to system load, but the limit generally allows for creating/updating tens of thousands of objects an hour.
Handling Rate Limits
When integrating with a rate-limited API, our recommended best practice is to write your code in a way that handles 429 HTTP status codes in an HTTP response. When the rate limit is exceeded, HTTP response bodies will look like the following:
{
"error": {
"message": "Rate limit exceeded.",
"type": "invalid_request_error",
"userMessage": "Rate limit exceeded."
}
}If you receive a 429 HTTP status code from the API, we recommend that you use an exponential backoff strategy to retry requests. This involves repeatedly retrying the request, with a backoff delay that increases exponentially with every retried request, until a maximum delay is reached. A small random constant is also added to the delay time each time in order to avoid situations in which clients are retrying many requests in an exactly synchronized way. In pseudocode, a simplified example to illustrate this strategy might look something like the following:
def safe_api_get(url):
n = 1
maximum_delay = 15
while True:
try:
return api_get(url)
except RateLimitExceededException:
constant_factor = random_float_between(0, 1)
delay_time = 2 ** n + constant_factor
if delay_time > maximum_delay:
delay_time = maximum_delay
delay(delay_time)
n += 1How to Avoid Rate Limit Errors
Oftentimes, rate limit are reached when users try to perform certain types of bulk actions, such as creating hundreds of custom entities at once. When this occurs, users should identify where these calls are repetitively called, such as in various for and while loops. Where possible, these calls should be removed from those loops and a bulk endpoint should be leveraged instead. These differ from singular endpoints as they allow an array of inputs to be passed in a single API request rather than separate requests.
Examples of bulk vs singular endpoints include but are not limited to:
| Singular Endpoint | Bulk Endpoint | |
|---|---|---|
| DNA Seq - Create | createDNASequence | bulkCreateDNASequences |
| Custom Entities - Create | createCustomEntity | bulkCreateCustomEntities |
| Custom Entities - Update | updateCustomEntity | bulkUpdateCustomEntities |
| Container - Create | createContainer | bulkCreateContainers |
Example: Bulk Endpoints
In cases where you are looking to perform certain types of "bulk" actions, such as creating 1000 entities, you should use the bulk-create endpoint which makes 1 API call for an array of entities, rather than individual API calls for each entity.
When performing these types of repetitive actions, you should confirm whether there is an available bulk endpoint that can be leveraged.
def bulk_create(customEntitiesJSONList):
bulkJSON = {"customEntities":[]}
for entityJSON in customEntitiesJSONList:
bulkJSON["customEntities"].append(entityJSON)
if len(bulkJSON["customEntities"]) >= 100: # transact 100x entity-updates at a time
bulkUpdateCustomEntity(json.dumps(bulkJSON)) # make the API request with the list of 100 Custom Entities held currently
bulkJSON = {"customEntities":[]} # clear the Custom Entity array
if len(bulkJSON["customEntities"]) > 0:
patchBulkCustomEntity(json.dumps(bulkJSON)) # make final update for any [1,100) entities leftover
returnUsing the pseudocode above, a user looking to create 1000 entities would only make 10 API calls, each call creating 100 entities at a time. In contrast, if a user used the singular create endpoint, they would make 1000 distinct API calls to accomplish the same task.
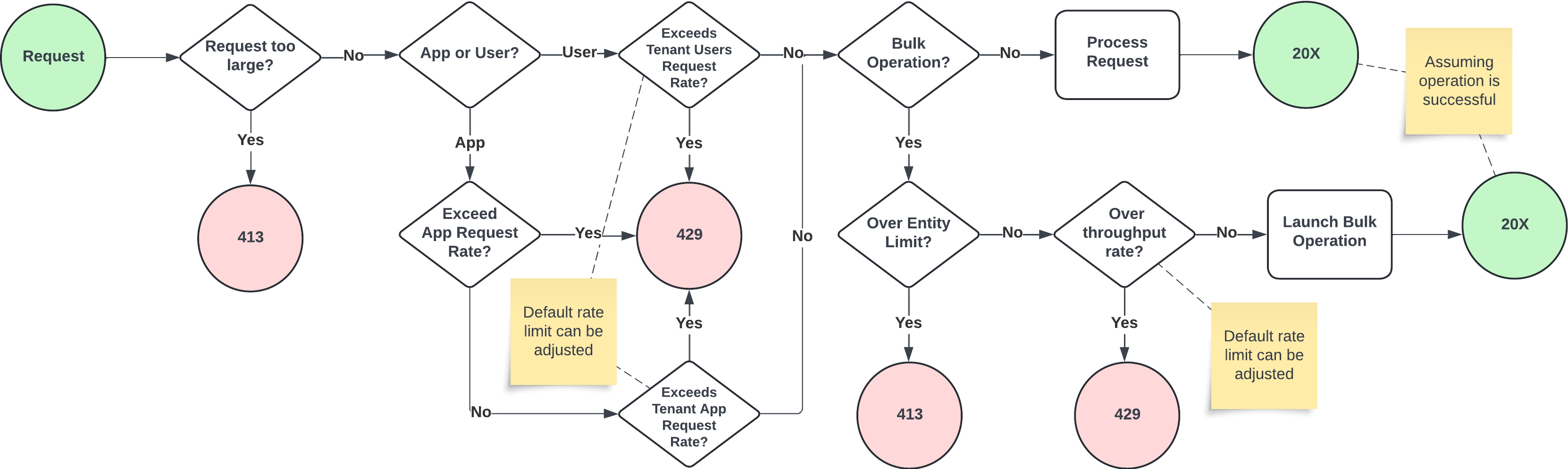
API Request Lifecycle
This diagram overviews how our data, request, and throughput limits interact:
Increasing your rate limit
API rate limits are configurable, and can be increased by Benchling support ([email protected]) upon request.
Updated about 2 months ago